
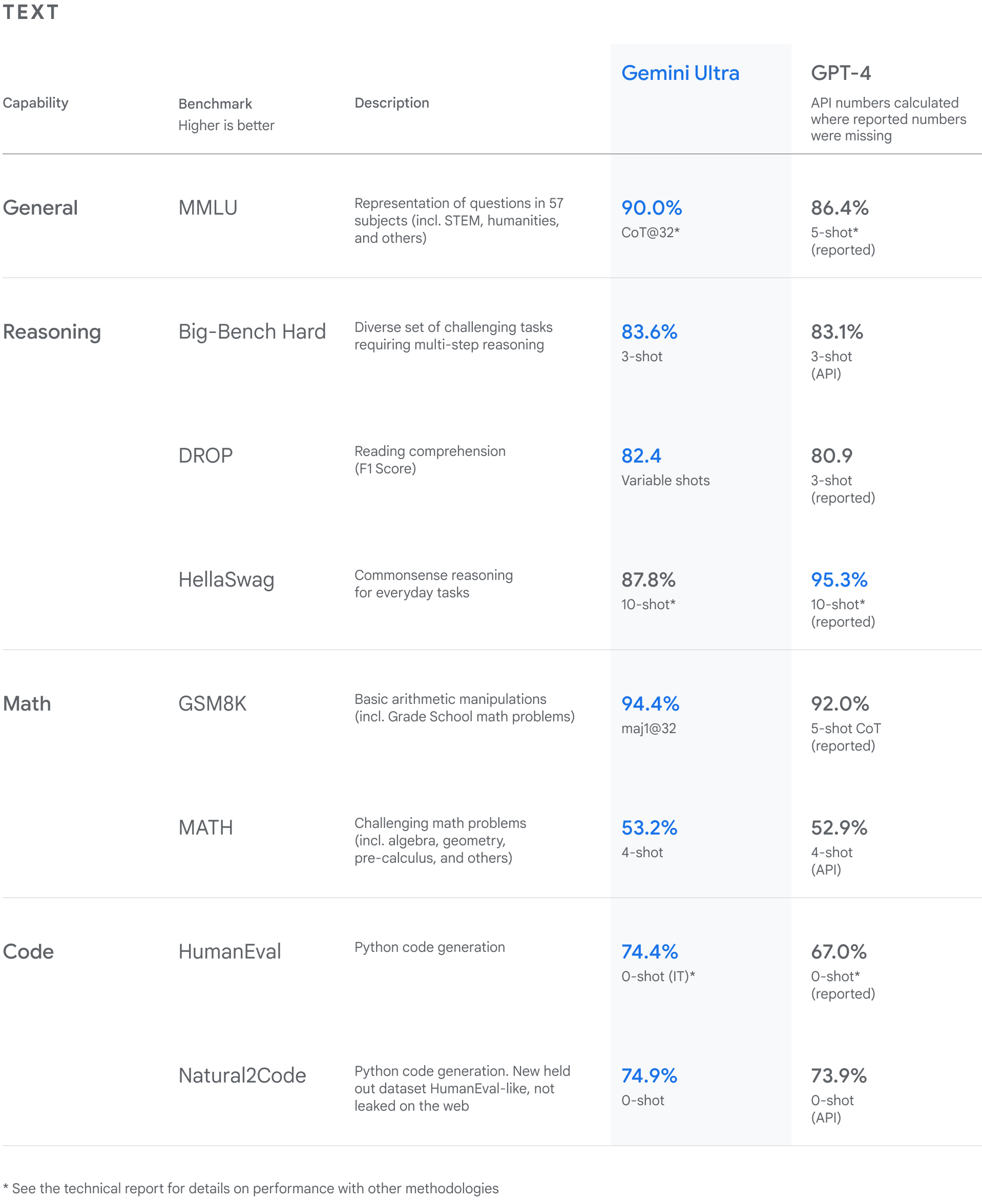
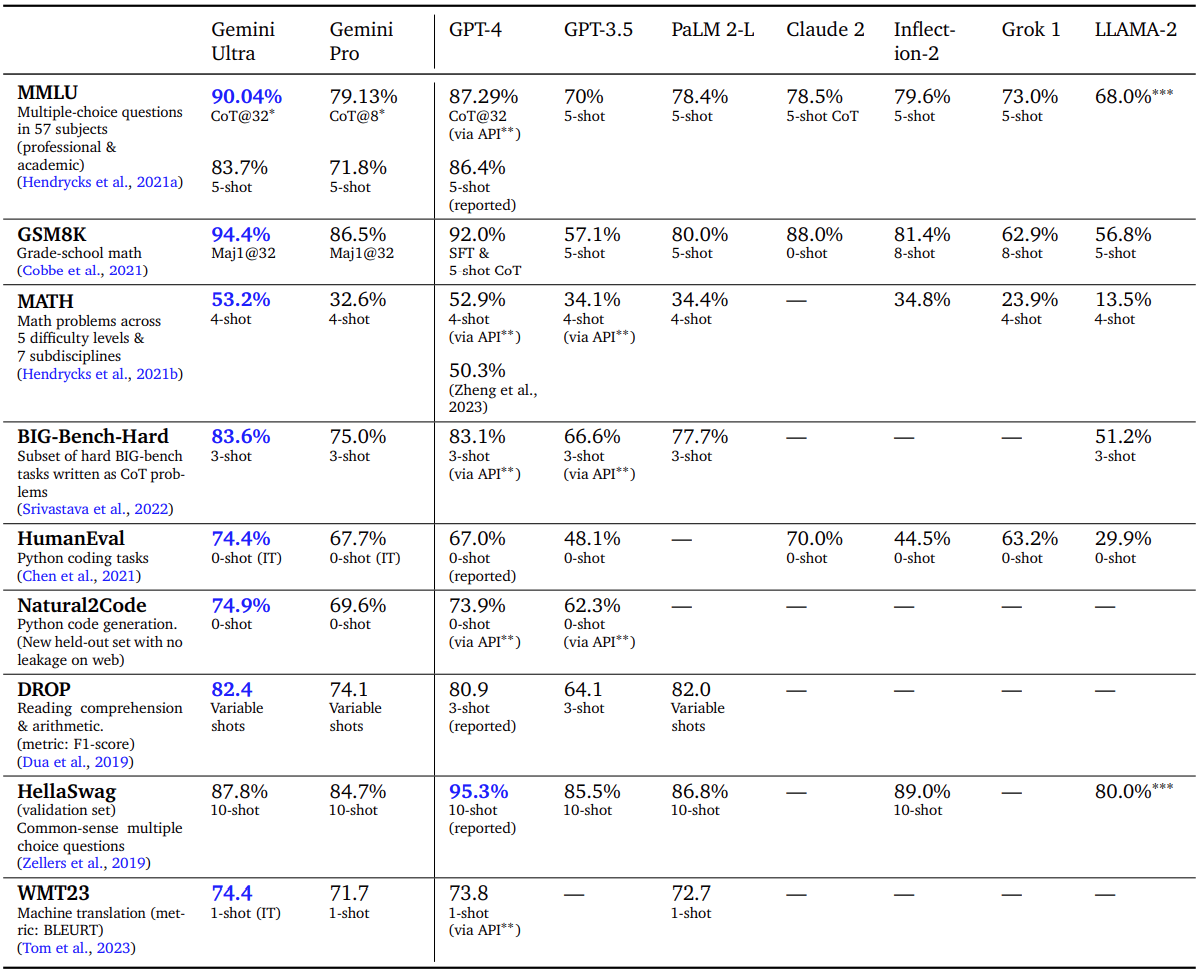
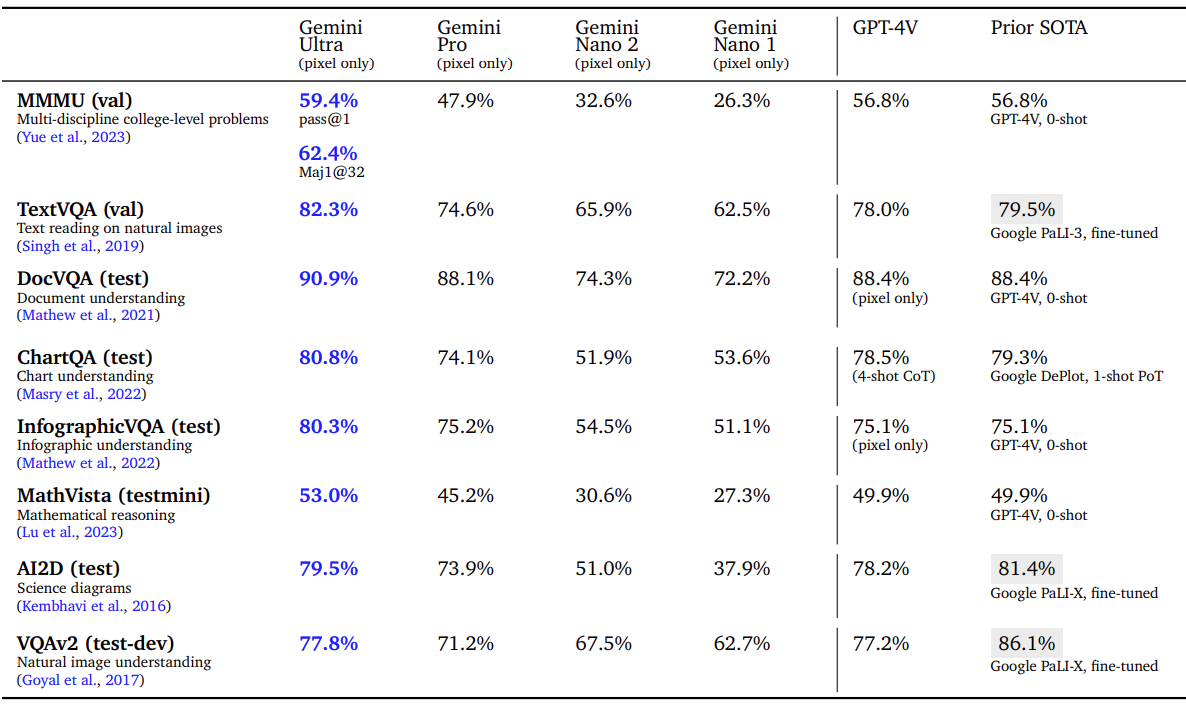
![{"type":"elementor","siteurl":"https://geminigoogle.cc/wp-json/","elements":[{"id":"6028727","elType":"widget","isInner":false,"isLocked":false,"settings":{"tabs":[{"tab_title":"Text ","tab_content":"<p><img class=\"wp-image-27 size-full aligncenter\" src=\"http://geminigoogle.cc/wp-content/uploads/2023/12/gemini_final_text_table_bigger_font_amendment_lines.gif\" alt=\"Our new benchmark approach to MMLU\" width=\"1917\" height=\"2350\"></p>","_id":"2bf5239"},{"tab_title":"MULTIMODAL","tab_content":"","_id":"3f263ee"}],"view":"traditional","type":"horizontal","tabs_align_horizontal":"","tabs_align_vertical":"","navigation_width":{"unit":"%","size":"","sizes":[]},"border_width":{"unit":"px","size":1,"sizes":[]},"border_color":"","background_color":"","tab_color":"","tab_active_color":"","tab_typography_typography":"","tab_typography_font_family":"","tab_typography_font_size":{"unit":"px","size":"","sizes":[]},"tab_typography_font_size_tablet":{"unit":"px","size":"","sizes":[]},"tab_typography_font_size_mobile":{"unit":"px","size":"","sizes":[]},"tab_typography_font_weight":"","tab_typography_text_transform":"","tab_typography_font_style":"","tab_typography_text_decoration":"","tab_typography_line_height":{"unit":"px","size":"","sizes":[]},"tab_typography_line_height_tablet":{"unit":"em","size":"","sizes":[]},"tab_typography_line_height_mobile":{"unit":"em","size":"","sizes":[]},"tab_typography_letter_spacing":{"unit":"px","size":"","sizes":[]},"tab_typography_letter_spacing_tablet":{"unit":"px","size":"","sizes":[]},"tab_typography_letter_spacing_mobile":{"unit":"px","size":"","sizes":[]},"tab_typography_word_spacing":{"unit":"px","size":"","sizes":[]},"tab_typography_word_spacing_tablet":{"unit":"em","size":"","sizes":[]},"tab_typography_word_spacing_mobile":{"unit":"em","size":"","sizes":[]},"text_stroke_text_stroke_type":"","text_stroke_text_stroke":{"unit":"px","size":"","sizes":[]},"text_stroke_text_stroke_tablet":{"unit":"px","size":"","sizes":[]},"text_stroke_text_stroke_mobile":{"unit":"px","size":"","sizes":[]},"text_stroke_stroke_color":"#000","title_shadow_text_shadow_type":"","title_shadow_text_shadow":{"horizontal":0,"vertical":0,"blur":10,"color":"rgba(0,0,0,0.3)"},"title_align":"","content_color":"","content_typography_typography":"","content_typography_font_family":"","content_typography_font_size":{"unit":"px","size":"","sizes":[]},"content_typography_font_size_tablet":{"unit":"px","size":"","sizes":[]},"content_typography_font_size_mobile":{"unit":"px","size":"","sizes":[]},"content_typography_font_weight":"","content_typography_text_transform":"","content_typography_font_style":"","content_typography_text_decoration":"","content_typography_line_height":{"unit":"px","size":"","sizes":[]},"content_typography_line_height_tablet":{"unit":"em","size":"","sizes":[]},"content_typography_line_height_mobile":{"unit":"em","size":"","sizes":[]},"content_typography_letter_spacing":{"unit":"px","size":"","sizes":[]},"content_typography_letter_spacing_tablet":{"unit":"px","size":"","sizes":[]},"content_typography_letter_spacing_mobile":{"unit":"px","size":"","sizes":[]},"content_typography_word_spacing":{"unit":"px","size":"","sizes":[]},"content_typography_word_spacing_tablet":{"unit":"em","size":"","sizes":[]},"content_typography_word_spacing_mobile":{"unit":"em","size":"","sizes":[]},"content_shadow_text_shadow_type":"","content_shadow_text_shadow":{"horizontal":0,"vertical":0,"blur":10,"color":"rgba(0,0,0,0.3)"},"_title":"","_margin":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_margin_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_margin_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_padding_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_element_width":"","_element_width_tablet":"","_element_width_mobile":"","_element_custom_width":{"unit":"%","size":"","sizes":[]},"_element_custom_width_tablet":{"unit":"px","size":"","sizes":[]},"_element_custom_width_mobile":{"unit":"px","size":"","sizes":[]},"_flex_align_self":"","_flex_align_self_tablet":"","_flex_align_self_mobile":"","_flex_order":"","_flex_order_tablet":"","_flex_order_mobile":"","_flex_order_custom":"","_flex_order_custom_tablet":"","_flex_order_custom_mobile":"","_flex_size":"","_flex_size_tablet":"","_flex_size_mobile":"","_flex_grow":1,"_flex_grow_tablet":"","_flex_grow_mobile":"","_flex_shrink":1,"_flex_shrink_tablet":"","_flex_shrink_mobile":"","_element_vertical_align":"","_element_vertical_align_tablet":"","_element_vertical_align_mobile":"","_position":"","_offset_orientation_h":"start","_offset_x":{"unit":"px","size":"0","sizes":[]},"_offset_x_tablet":{"unit":"px","size":"","sizes":[]},"_offset_x_mobile":{"unit":"px","size":"","sizes":[]},"_offset_x_end":{"unit":"px","size":"0","sizes":[]},"_offset_x_end_tablet":{"unit":"px","size":"","sizes":[]},"_offset_x_end_mobile":{"unit":"px","size":"","sizes":[]},"_offset_orientation_v":"start","_offset_y":{"unit":"px","size":"0","sizes":[]},"_offset_y_tablet":{"unit":"px","size":"","sizes":[]},"_offset_y_mobile":{"unit":"px","size":"","sizes":[]},"_offset_y_end":{"unit":"px","size":"0","sizes":[]},"_offset_y_end_tablet":{"unit":"px","size":"","sizes":[]},"_offset_y_end_mobile":{"unit":"px","size":"","sizes":[]},"_z_index":"","_z_index_tablet":"","_z_index_mobile":"","_element_id":"","_css_classes":"","_animation":"","_animation_tablet":"","_animation_mobile":"","animation_duration":"","_animation_delay":"","_transform_rotate_popover":"","_transform_rotateZ_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateZ_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateZ_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotate_3d":"","_transform_rotateX_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateX_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateX_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect":{"unit":"px","size":"","sizes":[]},"_transform_rotateY_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_perspective_effect":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translate_popover":"","_transform_translateX_effect":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scale_popover":"","_transform_keep_proportions":"yes","_transform_scale_effect":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_mobile":{"unit":"px","size":"","sizes":[]},"_transform_skew_popover":"","_transform_skewX_effect":{"unit":"px","size":"","sizes":[]},"_transform_skewX_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewX_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect":{"unit":"px","size":"","sizes":[]},"_transform_skewY_effect_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_flipX_effect":"","_transform_flipY_effect":"","_transform_rotate_popover_hover":"","_transform_rotateZ_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateZ_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateZ_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotate_3d_hover":"","_transform_rotateX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateX_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateX_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_rotateY_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_rotateY_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_perspective_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_perspective_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translate_popover_hover":"","_transform_translateX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateX_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_translateY_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scale_popover_hover":"","_transform_keep_proportions_hover":"yes","_transform_scale_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scale_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleX_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover_tablet":{"unit":"px","size":"","sizes":[]},"_transform_scaleY_effect_hover_mobile":{"unit":"px","size":"","sizes":[]},"_transform_skew_popover_hover":"","_transform_skewX_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_skewX_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewX_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_hover":{"unit":"px","size":"","sizes":[]},"_transform_skewY_effect_hover_tablet":{"unit":"deg","size":"","sizes":[]},"_transform_skewY_effect_hover_mobile":{"unit":"deg","size":"","sizes":[]},"_transform_flipX_effect_hover":"","_transform_flipY_effect_hover":"","_transform_transition_hover":{"unit":"px","size":"","sizes":[]},"motion_fx_transform_x_anchor_point":"","motion_fx_transform_x_anchor_point_tablet":"","motion_fx_transform_x_anchor_point_mobile":"","motion_fx_transform_y_anchor_point":"","motion_fx_transform_y_anchor_point_tablet":"","motion_fx_transform_y_anchor_point_mobile":"","_background_background":"","_background_color":"","_background_color_stop":{"unit":"%","size":0,"sizes":[]},"_background_color_b":"#f2295b","_background_color_b_stop":{"unit":"%","size":100,"sizes":[]},"_background_gradient_type":"linear","_background_gradient_angle":{"unit":"deg","size":180,"sizes":[]},"_background_gradient_position":"center center","_background_image":{"url":"","id":"","size":""},"_background_image_tablet":{"url":"","id":"","size":""},"_background_image_mobile":{"url":"","id":"","size":""},"_background_position":"","_background_position_tablet":"","_background_position_mobile":"","_background_xpos":{"unit":"px","size":0,"sizes":[]},"_background_xpos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_xpos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_ypos":{"unit":"px","size":0,"sizes":[]},"_background_ypos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_ypos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_attachment":"","_background_repeat":"","_background_repeat_tablet":"","_background_repeat_mobile":"","_background_size":"","_background_size_tablet":"","_background_size_mobile":"","_background_bg_width":{"unit":"%","size":100,"sizes":[]},"_background_bg_width_tablet":{"unit":"px","size":"","sizes":[]},"_background_bg_width_mobile":{"unit":"px","size":"","sizes":[]},"_background_video_link":"","_background_video_start":"","_background_video_end":"","_background_play_once":"","_background_play_on_mobile":"","_background_privacy_mode":"","_background_video_fallback":{"url":"","id":"","size":""},"_background_slideshow_gallery":[],"_background_slideshow_loop":"yes","_background_slideshow_slide_duration":5000,"_background_slideshow_slide_transition":"fade","_background_slideshow_transition_duration":500,"_background_slideshow_background_size":"","_background_slideshow_background_size_tablet":"","_background_slideshow_background_size_mobile":"","_background_slideshow_background_position":"","_background_slideshow_background_position_tablet":"","_background_slideshow_background_position_mobile":"","_background_slideshow_lazyload":"","_background_slideshow_ken_burns":"","_background_slideshow_ken_burns_zoom_direction":"in","_background_hover_background":"","_background_hover_color":"","_background_hover_color_stop":{"unit":"%","size":0,"sizes":[]},"_background_hover_color_b":"#f2295b","_background_hover_color_b_stop":{"unit":"%","size":100,"sizes":[]},"_background_hover_gradient_type":"linear","_background_hover_gradient_angle":{"unit":"deg","size":180,"sizes":[]},"_background_hover_gradient_position":"center center","_background_hover_image":{"url":"","id":"","size":""},"_background_hover_image_tablet":{"url":"","id":"","size":""},"_background_hover_image_mobile":{"url":"","id":"","size":""},"_background_hover_position":"","_background_hover_position_tablet":"","_background_hover_position_mobile":"","_background_hover_xpos":{"unit":"px","size":0,"sizes":[]},"_background_hover_xpos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_hover_xpos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos_tablet":{"unit":"px","size":0,"sizes":[]},"_background_hover_ypos_mobile":{"unit":"px","size":0,"sizes":[]},"_background_hover_attachment":"","_background_hover_repeat":"","_background_hover_repeat_tablet":"","_background_hover_repeat_mobile":"","_background_hover_size":"","_background_hover_size_tablet":"","_background_hover_size_mobile":"","_background_hover_bg_width":{"unit":"%","size":100,"sizes":[]},"_background_hover_bg_width_tablet":{"unit":"px","size":"","sizes":[]},"_background_hover_bg_width_mobile":{"unit":"px","size":"","sizes":[]},"_background_hover_video_link":"","_background_hover_video_start":"","_background_hover_video_end":"","_background_hover_play_once":"","_background_hover_play_on_mobile":"","_background_hover_privacy_mode":"","_background_hover_video_fallback":{"url":"","id":"","size":""},"_background_hover_slideshow_gallery":[],"_background_hover_slideshow_loop":"yes","_background_hover_slideshow_slide_duration":5000,"_background_hover_slideshow_slide_transition":"fade","_background_hover_slideshow_transition_duration":500,"_background_hover_slideshow_background_size":"","_background_hover_slideshow_background_size_tablet":"","_background_hover_slideshow_background_size_mobile":"","_background_hover_slideshow_background_position":"","_background_hover_slideshow_background_position_tablet":"","_background_hover_slideshow_background_position_mobile":"","_background_hover_slideshow_lazyload":"","_background_hover_slideshow_ken_burns":"","_background_hover_slideshow_ken_burns_zoom_direction":"in","_background_hover_transition":{"unit":"px","size":"","sizes":[]},"_border_border":"","_border_width":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_width_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_width_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_color":"","_border_radius":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_box_shadow_box_shadow_type":"","_box_shadow_box_shadow":{"horizontal":0,"vertical":0,"blur":10,"spread":0,"color":"rgba(0,0,0,0.5)"},"_box_shadow_box_shadow_position":" ","_border_hover_border":"","_border_hover_width":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_width_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_width_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_hover_color":"","_border_radius_hover":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_hover_tablet":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_border_radius_hover_mobile":{"unit":"px","top":"","right":"","bottom":"","left":"","isLinked":true},"_box_shadow_hover_box_shadow_type":"","_box_shadow_hover_box_shadow":{"horizontal":0,"vertical":0,"blur":10,"spread":0,"color":"rgba(0,0,0,0.5)"},"_box_shadow_hover_box_shadow_position":" ","_border_hover_transition":{"unit":"px","size":"","sizes":[]},"_mask_switch":"","_mask_shape":"circle","_mask_image":{"url":"","id":"","size":""},"_mask_notice":"","_mask_size":"contain","_mask_size_tablet":"","_mask_size_mobile":"","_mask_size_scale":{"unit":"%","size":100,"sizes":[]},"_mask_size_scale_tablet":{"unit":"px","size":"","sizes":[]},"_mask_size_scale_mobile":{"unit":"px","size":"","sizes":[]},"_mask_position":"center center","_mask_position_tablet":"","_mask_position_mobile":"","_mask_position_x":{"unit":"%","size":0,"sizes":[]},"_mask_position_x_tablet":{"unit":"px","size":"","sizes":[]},"_mask_position_x_mobile":{"unit":"px","size":"","sizes":[]},"_mask_position_y":{"unit":"%","size":0,"sizes":[]},"_mask_position_y_tablet":{"unit":"px","size":"","sizes":[]},"_mask_position_y_mobile":{"unit":"px","size":"","sizes":[]},"_mask_repeat":"no-repeat","_mask_repeat_tablet":"","_mask_repeat_mobile":"","hide_desktop":"","hide_tablet":"","hide_mobile":""},"defaultEditSettings":{"defaultEditRoute":"content"},"elements":[],"widgetType":"tabs","editSettings":{"defaultEditRoute":"content","panel":{"activeTab":"content","activeSection":"section_tabs"},"activeItemIndex":2}}]}](http://geminigoogle.cc/wp-content/uploads/2023/12/gemini_final_multimodal_table_bigger_font_amendment_lines-scaled.gif)
Gemini Ultra model is prompted with one example of interleaved image and text where the user provides two colors (blue and yellow) and image suggestions of creating a cute blue cat or a blue dog with yellow ear from yarn. The model is then given two new colors (pink and green) and asked for two ideas about what to create using these colors. The model successfully generates an interleaved sequence of images and text with suggestions to create a cute green avocado with pink seed or a green bunny with pink ears from yarn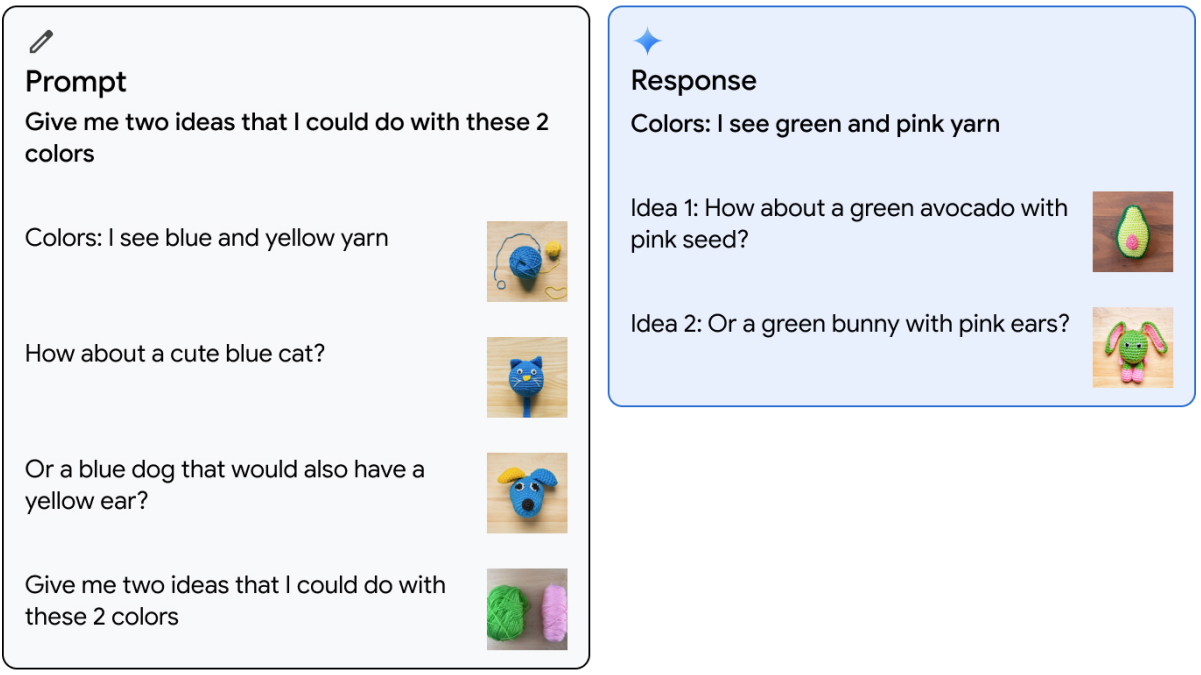
Verifying a student’s solution to a physics problem. The model is able to correctly recognize all of the handwritten content and verify the reasoning. On top of understanding the text in the image, it needs to understand the problem setup and correctly follow instructions to generate LATEX.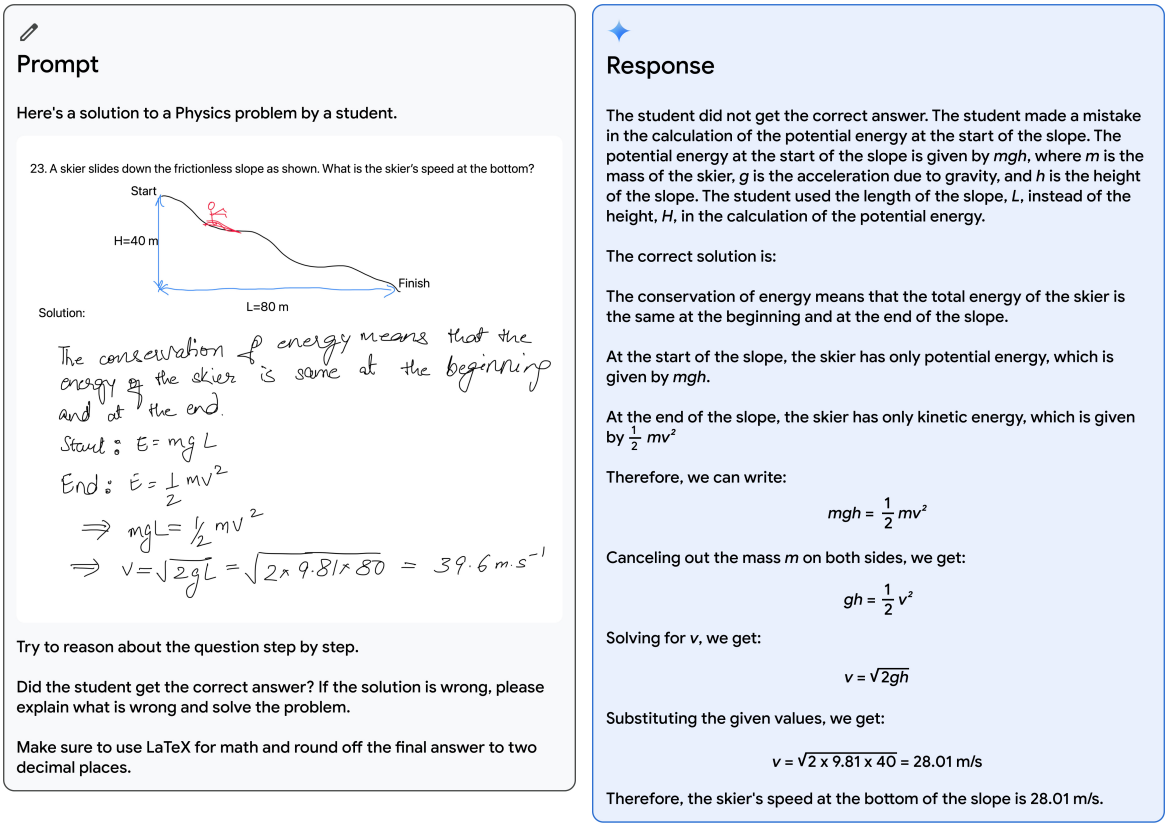
Consider a cooking scenario about making an omelet where we prompt the model with a sequence of audio and images. Table 13 indicates a turn-by-turn interaction with the model, providing pictures and verbally asking questions about the next steps for cooking an omelet. We note that the model response text is reasonably accurate, and shows that model processes fine-grained image details to
evaluate when the omelet is fully cooked. See demo on the website





Explanation of humor in a meme. The model is showing the ability to not only describe what is happening in the image but also what it means even though the cultural context is not mentioned explicitly in the image or the prompt. Source: Hwang and Shwartz (2023).
Common-sense reasoning in images. The model is able to understand the relationships represented in the graphs and reason about them in a multilingual setting. Source: image created by an author from the Gemini team
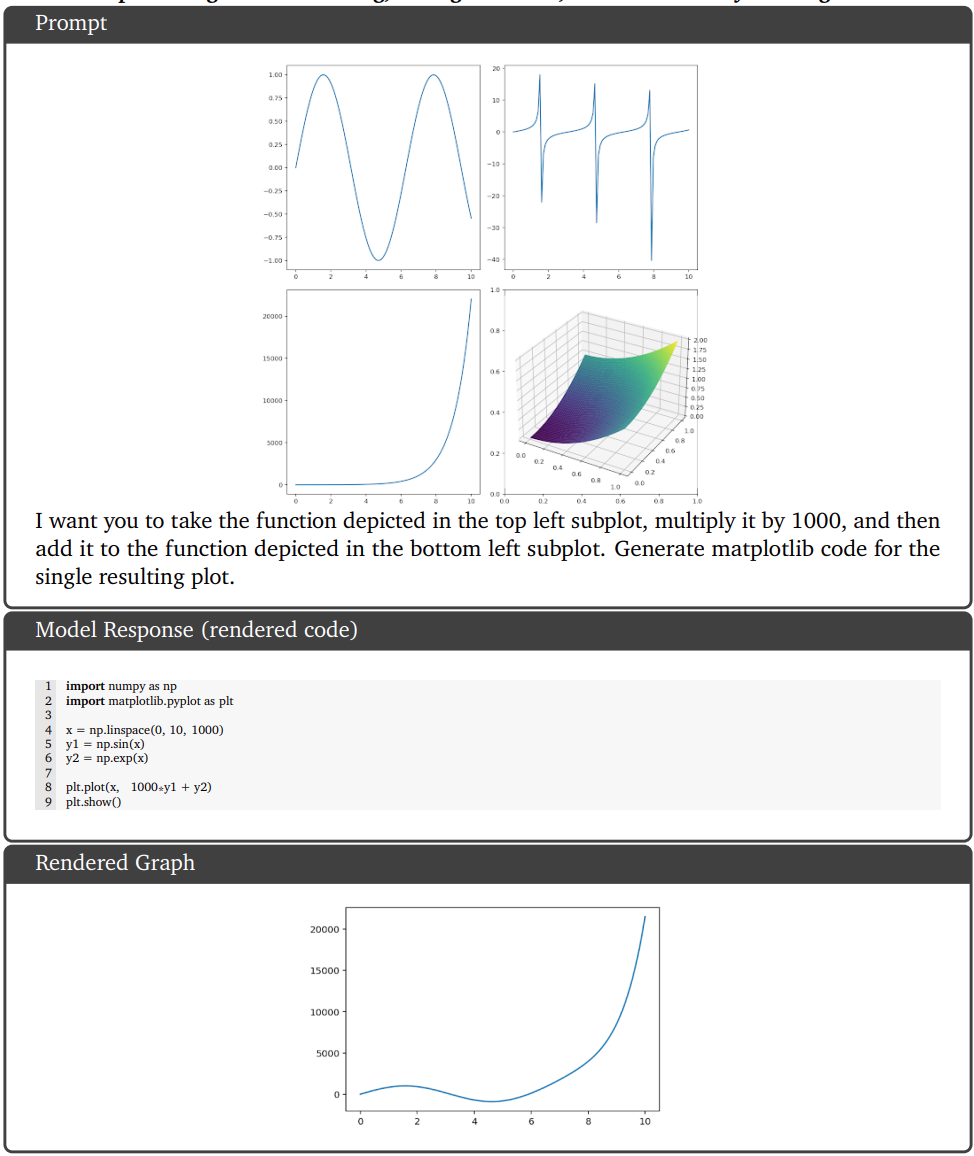
Multimodal reasoning capabilities applied to code generation. Gemini Ultra needs to perform inverse graphics task to infer the code that would have generated the plots, perform additional mathematical transformations, and generate relevant code.
